
Немного о RTOS
Когда необходимо выполнять несколько действий (процессов/задач) одновременно на микроконтроллере, обычно мы задумываемся об использовании RTOS (Real Time Operating System). RTOS обычно занимает несколько дополнительных килобайт памяти. В то же время для приложений RTOS может добавить больше сложности, в том числе при отладке.
Большинство RTOS использует алгоритм упреждающего планирования. С помощью использования прерывания текущий выполняемый процесс приостанавливается и вызывается планировщик задач, чтобы определить, какой процесс должен выполняться следующим. Процессы получают некоторое количество процессорного времени небольшими порциями. Суммарная длительность времени, получаемого процессом, зависит от его приоритета. Все процессы обычно представляют собой бесконечные циклы.
Происходит прерывание одного задания, сохранение и переключение контекста. Операции переключения между заданиями требуют несколько дополнительных операций со стороны операционной системы.
Есть ли способ обойтись без RTOS, и в то же время обеспечить многозадачность?
Можно ли выполнять десятки различных задач одновременно на простых микроконтроллерах, не прибегая к помощи RTOS? Сегодня мы рассмотрим подход, который позволит выполнять несколько заданий одновременно, при этом дополнительно использовав очень маленький объем памяти микроконтроллера. Подход, который позволит оставлять процедуры прерываний быстрыми и в то же время контролировать многозадачность простым и прозрачным способом.
Несколько ключевых моментов, которые предполагают использование этого подхода:
-
Если отклик в реальном времени не обязателен и может быть задержан на несколько микросекунд или миллисекунд. В большинстве задач моментальный отклик на события не играет большой роли. Например, если дверь начнет открываться через одну миллисекунду, или светодиод включится через 1 миллисекунду, или нажатие кнопки сработает через одну миллисекунду, это не будет играть большой роли. Иногда, наоборот, считывание событий с задержкой более надежно, например, в случае дребезга контакта при нажатии кнопки).
-
Непрерывность процесса более важна, чем, т.н. реакция реального времени, если мы не хотим, чтобы наш процесс был внезапно прерван на существенное время, чтобы отдать временной слот другому процессу.
-
Никакой RTOS не портирован на Вашу платформу, например, в случае контроллеров с маленьким объёмом памяти и дешевых микроконтроллеров (старых, в том числе)
-
У Вас недостаточно времени для изучения RTOS
-
Вы хотите простой путь получения многозадачности
-
У Вас нет свободных ресурсов для разворачивания RTOS
Суть метода
- Разделите все Ваши задачи на группы: медленно исполняемые (необходимы длительные ожидания событий внутри), средние (кратковременные задержки внутри) и быстрейшие (простые, быстро исполняемые - линейные и без задержек).
- Создайте для каждого типа задач очередь указателей на эти задачи (указателей на функции/процедуры)
- Исполняйте быстрые функции/процедуры вместо ожиданий внутри средних функций.
- Используйте средние и быстрые для ожидания внутри медленных.
На этом рисунке схематично изображена медленная функция, средняя функция и быстрая функция и три очереди указателей на эти функции (очереди FIFO):

Примеры быстрых задач, исполняющихся в течение нескольких микросекунд:
- установка инструкций прямого доступа к памяти переноса данных из массива
- инструкции реакции на события, обычно используемые внутри прерывания
- простые вычисления
Примеры средних задач:
- чтение периферии, например, АЦП polling, SPI, I2C, UART… коммуникации с ожиданием ответа (температурные, барометрические, газовые... сенсоры)
- сложные вычисления
- ожидание передачи большого количества данных без помощи контроллера прямого доступа к памяти
- задачи с ожиданием усреднения результата (АЦП, дребезг клавиш)
Примеры медленных задач:
- ожидание реакции пользователя на событие, например, нажатие клавиши
- ожидание ответа модема на АТ-команды в ходе коммуникации с удаленным абонентом
- передача данных по WiFi на удаленный сервер
- отображение информации на дисплее
Реализация на Си
На фрагменте ниже приведен пример простейшей имплементации на языке Cи для одной очереди.
#define Q_SIZE_FAST 16
volatile int F1_last; // последний элемент в очереди
int F1_first; // первый элемент в очереди
void (*F1_Queue[Q_SIZE_FAST])(); //очередь указателей на функции(процедуры)
void DummyF(void){;}
void F1_QueueIni(void){ // инициализация очереди
F1_last = 0;
F1_first = 0;
}
int F1_push(void (*pointerQ)(void)){ // добавить элемент в очередь
if ((F1_last+1)%Q_SIZE_FAST == F1_first)return 1;
F1_Queue[F1_last++] = pointerQ;
F1_last%=Q_SIZE_FAST;
return 0;
}
void (*F1_pull(void))(void){ // взять элемент из очереди -
//возвращает указатель
void (*pullVar)(void);
if (F1_last == F1_first)return DummyF;
pullVar = F1_Queue[F1_first++];
F1_first%=Q_SIZE_FAST;
return pullVar;
}
Как видим, здесь всего несколько строчек кода, и этого, в общем-то, достаточно для разворачивания многозадачной системы. Здесь объявлена очередь указателей на функции, функция инициализации, функция добавления указателей на функции в очередь. Вот всё, что нужно для использования одной очереди.
Формирование задержек можно обеспечить, ожидая на очереди. Пример реализации функции ожидания ниже:
void DelayOnF1(uint64_t delay){
uint64_t targetTime = delay + millis();
while(millis()<targetTime)F1_pull()();
}
Здесь millis() возвращает значения счётчика миллисекунд с начала запуска программы (volatile uint64_t, инкрементируемое по таймеру раз в 1 миллисекунду).
Если необходимо больше очередей, необходимо сделать то же самое для других очередей. Все очереди получаются тогда контентно независимыми.
Простейший пример использования
в main.c:
….
F1_QueueIni();
F2_QueueIni();
F3_QueueIni();
F4_QueueIni();
for(;;){
F1_pull()();
F2_pull()();
F3_pull()();
F4_pull()();
}
Внутри обработчика одного прерывания:
F1_push(LED_On_Off);
Внутри другого:
F2_push(CalculateTemperatureMiddleValue);
Внутри третьего:
F3_push(Display_ScreenInfo);
Внутри четвёртого:
F4_push(ScanKeyBoard);
Если прерывания имеют одинаковый приоритет и не вытесняют друг друга - можно добавлять указатели в одну и ту же очередь (not nested, tail chaining interrupts).
Передача параметров
При необходимости передачи в функции внутри очереди параметров можно использовать указатели на функции с параметрами и отдельную очередь с параметрами.
Пример имплементации ниже:
struct fParams { // структура для передачи параметров
int IntVar;
float FloatVar;
};
volatile int FP_last; // последний элемент в очереди
int FP_first; // первый элемент в очереди
void (*FP_Queue[Q_SIZE_FAST])(struct fParams *); //очередь указателей
//на функции
struct fParams PARAMS_array[Q_SIZE_FAST]; //очередь параметров
void FP_QueueIni(void){ // инициализация очереди
FP_last = 0;
FP_first = 0;
}
int FP_push(void (*pointerQ)(struct fParams *), struct fParams * parameterQ){ // добавить функцию очередь
if ((FP_last+1)%Q_SIZE_FAST == FP_first)return 1;
FP_Queue[FP_last] = pointerQ;
PARAMS_array[FP_last++] = *parameterQ;
FP_last%=Q_SIZE_FAST;
return 0;
}
void FP_pull(void){ // взять и выполнить функцию из очереди, передав ей параметры -
void (*pullVar)(struct fParams *);
struct fParams * Params;
if (FP_last == FP_first)return;
Params = &PARAMS_array[FP_first];
pullVar = FP_Queue[FP_first++];
FP_first %= Q_SIZE_FAST;
pullVar(Params);
}
Небольшой пример:
main.c:
FP_QueueIni();
while(1){
FP_pull();
}
Внутри прерывания:
FP_push(ApmControl,&(struct fParams){1,7.18}); //добавляем функцию AmpContol
// и передаём параметры 1 и 7.18
Ещё примеры
На этом рисунке мы видим фрагмент медленной задачи, которая использует ожидания на “средней” очереди
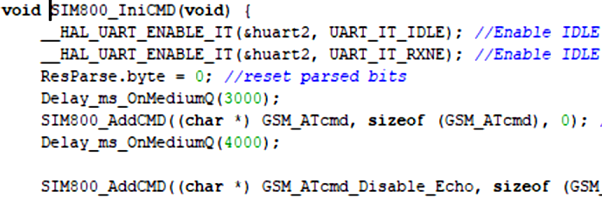
Не теряйте время на ожидание, если даже Вам необходимо ждать! Исполняйте задачи, вброшенные по прерываниям и иным событиям, ожидая своего события.
Пример утилизации времени ожидания с NoRTOS подходом:

Переписалось как:
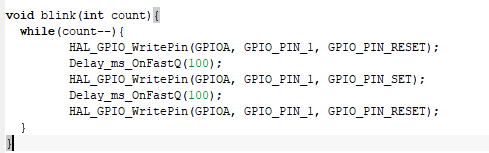
Вместо ожидания какого-либо события просто так ничего не делая - исполняйте задания из очередей:
Было:
while(SignalNotStable);
Стало:
while(SignalNotStable){S1_pull()();}
C++ реализация
Реализация на С++ позволяет сократить количество кода в случае использования множества очередей, с помощью конструктора можно создать очередь необходимой длины.
typedef void(*fP)(void);
class fQ {
private:
int first;
int last;
fP * fQueue;
int lengthQ;
public:
fQ(int sizeQ);
~fQ();
int push(fP); // добавить процедуру в очередь
int pull(void); // взять и выполнить процедуру из очереди
};
fQ::fQ(int sizeQ){ // инициализация очереди
fQueue = new fP[sizeQ];
last = 0;
first = 0;
lengthQ = sizeQ;
}
fQ::~fQ(){ // деинициализация очереди
delete [] fQueue;
}
int fQ::push(fP pointerF){ // добавить элемент в очередь
if ((last+1)%lengthQ == first){
return 1;
}
fQueue[last++] = pointerF;
last = last%lengthQ;
return 0;
}
int fQ::pull(void){ // взять элемент из очереди
if (last != first){
fQueue[first++]();
first = first%lengthQ;
return 0;
}
else{
return 1;
}
}
Пример использования:
fQ F1(16); //инициализируем очереди различной длины
fQ F2(12);
fQ A1(8);
int main(){
for(;;){
A1.pull();
usleep(10000); //спим по 10 миллисеунд
}
return 0;
}
Где-то в прерывании №1:
if(pin10.in == 1) F1.push(SwithOnRelay); else F1.push(SwithOffRelay);
Где-то в прерывании №2:
F2.push(ToggleLED);
Где-то в прерывании по таймеру - раз в 100 миллисекунд:
A1.push(UpdateUI);
Внутри UpdateUI:
void UpdateUI(void){
pin_CS_DISP.out = 0;
DelayOnF1(1); //задержка на 1 мс. на очереди - исполняем задания из очереди F1
DispLCD(Voltage);
DelayOnF2(1); //задержка на 1 мс. на очереди - исполняем задания из очереди F2
pin_CS_DISP.out = 1;
}
Преимущества
- Нетребовательный к ресурсам подход, позволяющий выполнять множество задач “параллельно”
- Задания не прерывают друг друга, простота отладки
- Легко масштабируется, прерывания с разными приоритетами могут иметь “свои” очереди
- Платформонезависимость - легкость разворачивания даже на самых простых микроконтроллерах
- Не требует длительного изучения
- Не требует дополнительных источников прерываний (нет планировщика заданий)
- Отсутствуют издержки, связанные с вытеснением заданий друг другом и сохранением их контекстов - существенная экономия времени и памяти
- Задания легко вбрасываются в очереди, сохраняя прерывания и другие важные фрагменты кода, где задержки не желательны, максимально быстрыми
- “Задания” могут добавлять сами себя в другие очереди заданий
- Позволяет эффективно утилизировать время ожидания, исполняя задания из очередей, при этом, в зависимости от времени предполагаемого ожидания. Можно ожидать, например на “средних” и “быстрых” функциях/процедурах внутри “медленных”, на “быстрых” внутри “средних”
Ранжирование задач может быть более глубоким, например: “быстрейшие”, “быстрые’, “средние”, “медленные”, “очень медленные”. Каждого вида очередей может быть по несколько штук.
by Aleksei Tertychnyi aka pinelab (доработанная статья опубликована на )